
Toggl Track has been evolving on top of a monolithic PostgreSQL database. However, we long struggled to serve OLAP usages of our data - meaning, our reporting features - while keeping the natural OLTP shape of our database. We strive daily to provide better reporting capabilities to our users, reporting over more data, with more insights, transformations, well... more of everything. But all of these reports were still running on top of our normalized data structure, on our transactional database.
Long story short, we long noticed the need to move, hydrate, and transform our transactional data into something with report-friendly structures, and that became harder and harder to ignore.
Moving data around
We started to look into what could be done, and what solutions were out there, but we ended up deciding to implement an in-house CDC pipeline, on which ETL processes would run, to build and keep up-to-date our new datasets. This, with a very important requirement in mind: keep our reporting features as close to real-time as they can be.
A periodic extraction wouldn't do it, while a CDC pipeline will provide us with a reliable stream of data changes happening on our transactional database - in a close to real-time fashion - and these change events could then be used to keep our OLAP transformations up-to-date. Along with other use cases.
The end goal is to reduce as much as possible run-time computing to transform data in order to deliver a given report. And make that data easy enough to be retrieved over different dimensions. Which often means sacrificing storage for computing.
Our OLAP journey
As so, our Postgres logical replication journey began. We chose to leverage Postgres functionalities to achieve our requirements, and in the end, our OLAP databases are also Postgres databases that are responsible not only for keeping our new datasets but also for doing much of the transformation's heavy lifting. Modularization was put in place to ensure that we can use different technologies if we choose to.
We are big Golang fans, so we build our logical replication client application - that will sit on top of Postgres logical replication features - in Golang, using pglogrepl, and end up with an implementation very very similar to other open-source snippets that you can find all over google. A very simplistic one too. But given our particular use case, we ended up extending that simplistic implementation with supporting features around uploading data-changing logical replication events to an event messaging service.
To make our logical replication client work, it needs a replication slot, on the Postgres side, the same as any other client, including Postgres itself. That slot will be responsible for keeping track of our client event consumption, and that is done by using LSN offsets.
LSNs, or Log Sequence Numbers, are incremental numbers that point to a given location in the WAL file. And that’s the “sequence” that we need to keep track of to commit our consumption progress to Postgres, in order to not receive the data again, but also to allow Postgres to flush old WAL files, which should no longer be needed, because we already consumed them (assuming that you have no other logical replication endeavors going on).
Here is an example of how these offsets look like, and a sample of queries that could generate such offset patterns:
| LSNs | Operation Sample |
|---|---|
| BEGIN 4/98EE65C0 INSERT 4/98EE65C0 UPDATE 4/98EE66D8 UPDATE 4/98EE6788 COMMIT 4/98EE6830 | START TRANSACTION; INSERT INTO track (description, duration) VALUES (‘Reading’, 360000); UPDATE track_total SET duration = duration + 360000; UPDATE user SET entries = entries + 1; COMMIT; |
| BEGIN 4/98EE6950 UPDATE 4/98EE6AD8 UPDATE 4/98EE6D28 UPDATE 4/98EE6DD8 COMMIT 4/98EE6F30 | START TRANSACTION; UPDATE track SET duration = duration + 360000; UPDATE track_total SET duration = duration + 360000; UPDATE users SET entries = entries + 1; COMMIT; |
| BEGIN 4/98EE6F68 INSERT 4/98EE6F68 COMMIT 4/98EE7040 | INSERT INTO users (email, password) VALUES (‘@.com’, ‘...’); |
In the first one, we have a transaction start, an insert, a couple of updates, and a commit - and by the way, this was one of the most common operation patterns that we had in our database till a few months ago. Then we have another example, and finally, how does it look like with a single insert. Notice the transaction's begin and end offsets, in contrast with what was writen before, that we cared only about data-changing events in the beginning of our journey.
Learning curve
That's an important bit of information regarding our journey there in the last sentence. We cared only for events that changed data, in order to fulfill our goal which was to keep our reporting dataset up-to-date. We cared for inserts, and updates. Also deletes, and truncates, but not to much about these, as we make these operations forbidden on our production databases. At least for non-superusers.
It made sense at the time because we knew that for a given data-changing event to make it into the Postgres logical replication stream, the change had to be already committed so... we didn’t see any use in processing any other events like transaction begins and ends. Looking back, that was a mistake.
To go easy on our eyes, from this point forward I'm just going to simplify LSN notation, from the hexadecimal representation to just a numeric sequence, prefixed with LSN. What's important here is for you to notice the value incrementation itself, or lack of it, not the representation.
| From | To |
|---|---|
| BEGIN 4/98EE7160 | BEGIN LSN000001 |
| BEGIN 4/98EE71C8 | BEGIN LSN000002 |
| BEGIN 4/98EE76D8 | BEGIN LSN000003 |
| BEGIN 4/98EE7788 | BEGIN LSN000004 |
| BEGIN 4/98EE7830 | BEGIN LSN000005 |
The examples shown to you till now have incremental LSN offsets. Meaning, we can see that the value of LSN offsets follows our operation order. This doesn't always happen, but it's something very easy to assume that it does. We fell for that.
Without concurrency, our Postgres data-changing queries will always produce incremental LSN offsets across the board. It makes sense, we are appending them to the log.
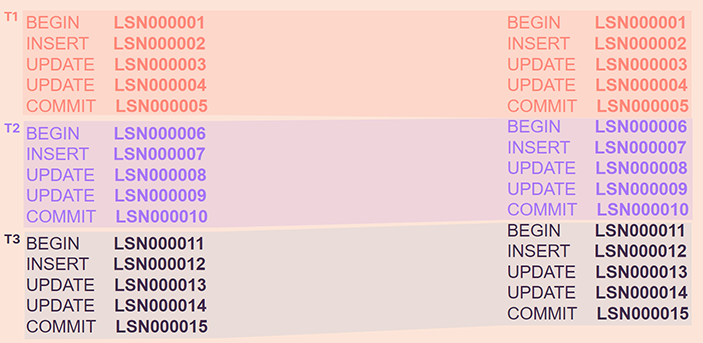
In the first column, we have the operations being executed, the transaction to which they belong, and the LSN values attributed to the individual operations. In the second column, we can see how these operations would be written to the log. We can visualize a WAL file being generated over such conditions as in the following image.
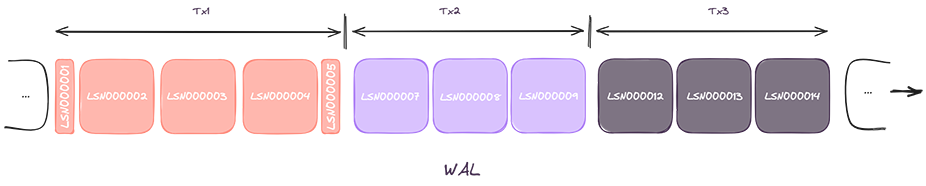
Notice in the first transaction, the BEGIN and END events there in the vertical, then abstracted in the others, because, well, we were not caring for them, but nonetheless they are there, and are streamed by Postgres - its just that - they were completely ignored by our logical replication client.
With concurrency, however, this is what LSN offsets look like:
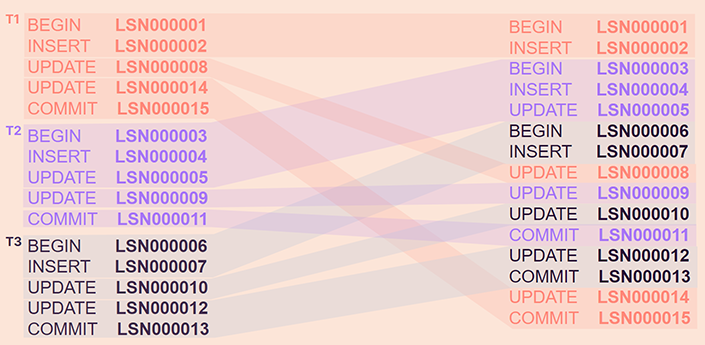
We can see that the first transaction started, Postgres logged the begin, the insert, then another transaction started, Postgres logged the first operations of it, then another one came in, same happened, and as the remaining changes reached the log offsets were given to them, but these incremental offsets don’t respect transaction boundaries. At the end of it, we get fragmented LSN incremental sequences, if we group them by transaction. Note that in this example, the first transaction to start is the last one to end.
Here is the visual representation of how a WAL file for a Postgres database operating under the right concurrency conditions may look like:
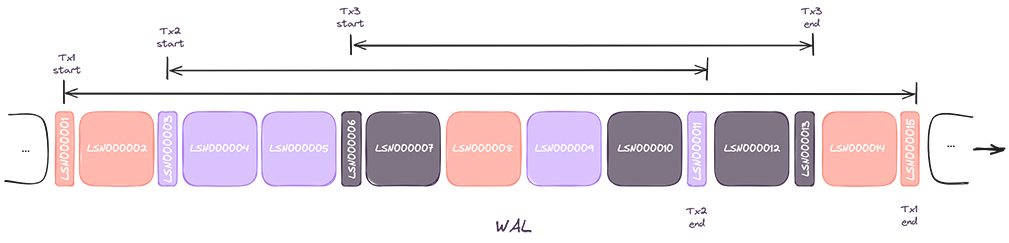
In sum, PostgreSQL will log concurrent transactions as their individual changes reach the log, and that’s the point where LSN offsets are attributed to individual events.
As we were intentionally disregarding transactions, all we had to work with were data-changing events and their offsets.
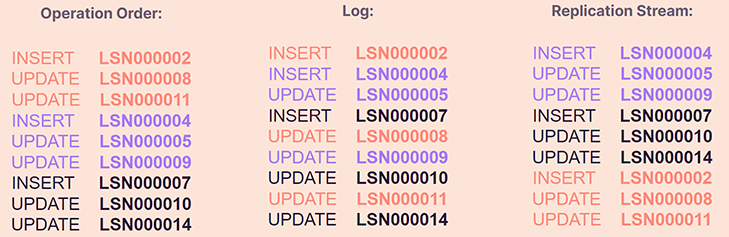
The operations that were being executed in one order, the first column - if they were being applied concurrently - pg will be logging the operations as they reach the log, second column. And logical replication would stream that data in a different order and with nonconsecutive incrementation within the transaction itself. Note again that the first transaction to start is the last one to be streamed.
We were dead set on caring only for data-changing events, we thought that it would simplify our process, and we didn’t yet realize that we needed to change that. So, we attempted to live with this reality that hit us once we first deployed to production. We would keep track of the LSN 1, 2, 3 whatever, commit that to Postgres, and eventually either end up ignoring data on our own, losing lower offsets, or receiving duplicated data for higher offsets.
We made bad assumptions, and the first one was that LSNs would always be incremental across the board, but as we just saw, when logging happens under concurrency conditions that’s not the case. The second was that we cared only for offsets coming in data-changing events. Since logical replication stream changes are already committed, we assumed that using data-changing events would be enough.
Attenuating circumstances
There were attenuating circumstances to our bad assumptions. One of which was that at the time, for the first usage of our newly developed OLAP - ETL-based - system, we didn't need to care for operation order. We were summing up time. So we didn’t look deep enough into how we were receiving the data, just if we were receiving all the data. And that always happened in close-to-ideal sceneries. For these aggregations didn't matter if we sum up 10 hours and subtract 5 or the other way around. And a side note is that deletes for us were actually negative updates. Because of soft-deletion.
Well, apart from that bad excuse of how we ended up scratching our heads about why we were getting inconsistent data on our OLAP transformations in production. We were also not generating the right conditions to test for concurrency issues, and that’s mostly why we didn’t have enough information to figure this out faster. We also managed to mitigate the problem so well, that we were now only seeing inconsistent data in production, and very sporadically, which masked the problem and didn’t help debug the issue. Eventually, we managed to trace down sporadic data inconsistencies to very specific conditions that would match our replication client redeploys with periods of high QPS, where the probability of ending up with non-incremental offsets between transactions would be greater.
Of course no user was exposed to this data till we got 100% confident that our extraction and transformations were reliable.
Enlightenment
Eventually, we figured out that we were doing something horribly wrong. The first clue was that - well - Postgres itself can use logical replication for replicas, and, replicas can also restart and/or recover without any data issues. The second one was to look at Postgres source code and understand the process behind pgoutput, which is the logical replication decoding plugin that we use. And third, and final breakthrough was getting in touch with Postgres developers in an act of desperation, through the mailing list, and slowly - navigating replies - put together the picture of how the replication offset tracking process works and how is expected to be used.
What did we do wrong?
Incremental LSN offsets are not ensured, not across transactions, nor should be expected. By doing so, we went into a spiral of "ways how not to track replication offsets", no matter how good our mitigation process was, was doomed to fail, specifically due to reconnections.
Given these two transactions, if we were to commit and use offset 5, we would then discard the first event of the next transaction artificially, and I say artificially because Postgres will still send it - as we are going to see next - but if we filter out events on our side using the last offset that we received, we will discard it.

Another wrong related to this was to commit operation offsets, instead of transaction end offsets. We were not caring for transaction events, so, when our client exited, we would commit the last data-changing event offset consumed, which would make Postgres stream the entire transaction again, and we would either duplicate that data or - if we were to artificially escape it - risking discarding needed data in other situations.

To be clear: no filtering on the client side is needed, we only assumed that was because we were fooled by Postgres resending the last transaction all over again as we were not committing transaction ends, only the last operation.
Postgres will only mark a given transaction as consumed by the logical replication client if the replication committed LSN is greater or equal to its transaction end.
Hard facts
After the realization of what we were doing wrong. We come to draw hard facts that we could rely on, to work towards a proper solution.
- Logical replication works over TCP, which means that we will never receive the next event, without acknowledging the last one, this ensures us that whatever offset comes next, is not "out-of-order" in the sense that it will be abiding by Postgres logical replication rules. We could also discard any networking interference in the process.
- The only event offset that we can rely on being incrementally-sequential in between transactions streamed by logical replication, is the commit or transaction end offset. Postgres will only log one transaction end at a time.
pgoutputlogical replication stream, will stream transactions sorted by commit offsets.- Not using transaction end offset to commit our consumption progress to the replication slot will trigger Postgres to resent the entire data for the current transaction again, upon reconnection.
- Events for a given transaction are always streamed together, regardless of the log position of events that compose it not being written sequentially in the log. This means that Postgres logical replication will only stream the next transaction once is done with the current one, and again TCP ensures that we can rely on this.
- Regardless of the consumption commit offset for the last transaction end having a higher numeric value than some of the next transaction events, PostgreSQL will always stream the next transaction in its entirety for the same reason that we were receiving duplicated events when not committing to Postgres an offset bigger or equal to the transaction end event.
New approach
We changed our approach to always commit the transaction end event offset to the Postgres replication slot, and only these offsets. For that, we make sure that we process the transaction data-changing events respecting the transactional integrity that they entail. Meaning, that we make sure that we upload all transaction data-changing events to our messaging service and only then advance our consumption offset.
At this point, we were confident that our logical replication client was working as expected. However, our tail doesn't end here.
Messaging services have limited message sizes, and as we started treating transaction data as a whole, we started to hit them. That is because Postgresql transactions can very well have millions of data-changing events. By moving forward only when the COMMIT event is received, and trying to enforce transaction integrity on data uploaded, we were vulnerable to OOM incidents. No matter how generously we would add memory to our service. On the other side, splitting these huge transactions into multiple bulk event uploads to respect max message size limitations would create conditions for duplication, either on plug-off events, or general erroring.
While the proper use of LSN offsets fully prevents data loss, it doesn’t prevent data duplication. At the end of the day, respecting transactional integrity while managing capacity constraints such as message sizes for our messaging service was not free of charge, and we ended up having to split transactions when their size was significant enough, due to that, under the wrong circumstances we may end up uploading only part of the transaction data, and that would mean that our consumption offset would not move forward because we didn’t consume the whole transaction. Upon retry we would resent the data already updated, causing data duplication. Another instance when data duplication can happen is if after delivery of the transaction data we are unable to commit our consumption offset to Postgres for some reason.
We embraced the data duplication possibility on our transformations to avoid thickening the consumption layer on top of Postgres (our Golang logical replication client) with statefulness features.
We are proud to announce that, if today you go to any Toggl Track client application, create an account, create your first project, and track time to it, the total time for that project that you will see across our client applications will be the result of this process. One in a few use cases that are already in production, in between other applications that we are working on.
Thanks for reading, we expect that sharing such adventures is helpful for others. Hoping that the next time that you need to work with Postgres logical replication, you don't get stuck around realizing these problems where you won’t find explicit answers in the documentation. And, unfortunately, can even be misled by implementations that are out there that simply don't care for data consistency, or the process as a whole, as we found in some open-source projects. Some went as far as suggesting in the documentation to just wait long enough for all the data to be consumed, which of course is impossible to do with a live application.
This post is based on the content of our A journey into postgresql logical replication session, presented at PGConf.EU 2023 last December.
